
Cultivating the Garden of Data With AWS DataZone
I have said it many times before, “Data is the new seed of innovation.”

Data stands as the foundational seed from which innovation sprouts, but how we manage and nurture this data determines whether we cultivate a thriving garden of insights or merely a compost heap of unsorted information. Enter Amazon DataZone.
What is Amazon DataZone?
Amazon DataZone is a data management service designed to streamline the process of cataloging, discovering, governing, sharing, and analyzing data. It acts as a centralized hub, allowing users to share and access data across accounts and supported regions. This service integrates seamlessly with various AWS services, including (but not limited to) Amazon Redshift, Amazon Athena, AWS Glue, and AWS Lake Formation.
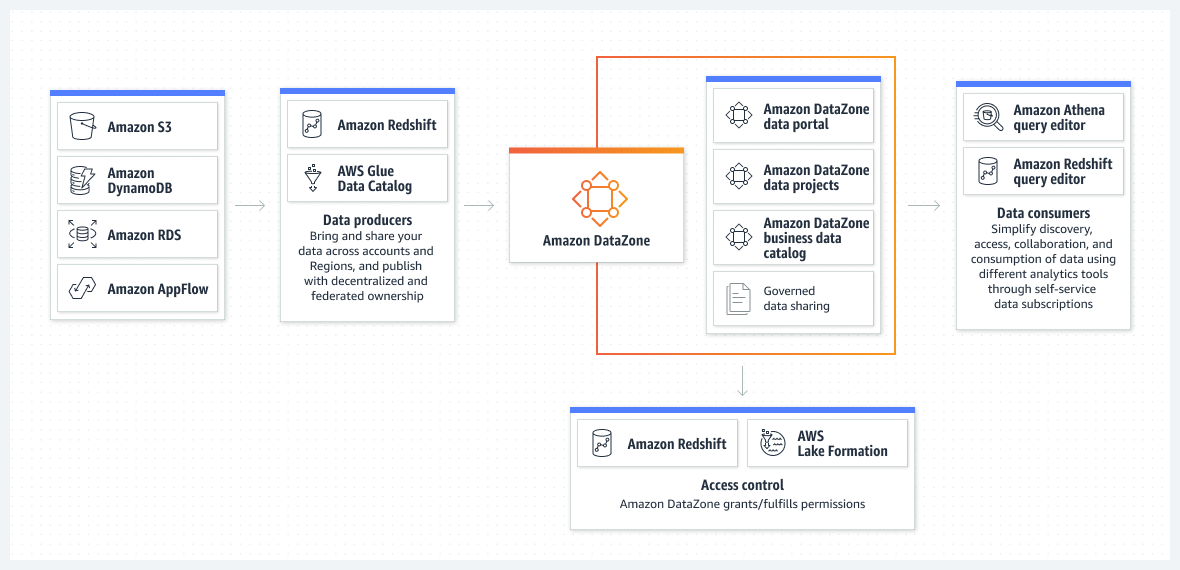
Key Features:
- Amazon DataZone Catalog: A unified platform that empowers businesses to start small and scale quickly. It allows different lines of business or teams to control their domain, share assets, and foster adoption across the organization.
- Collaboration Boost: Amazon DataZone promotes collaboration among data professionals, enabling them to work with assets and switch between tools of their choice effortlessly.
- Automated Catalog Hydration: With the power of large language models (LLMs), Amazon DataZone can auto-generate business names for structured data, making data discovery in the catalog a breeze.
- Interactivity: Amazon DataZone offers a unified data management portal, allowing users to collaborate and gain insights faster. It supports out-of-console experiences and provides APIs for programmatic interactions.
- Business Glossaries: Amazon DataZone supports business glossaries, acting as an organizational dictionary to maintain consistent definitions. This ensures clarity and uniformity when discovering and analyzing data.
Amazon DataZone and LLMs: A Symbiotic Relationship
One of the standout features of Amazon DataZone is its ability to automate catalog hydration using LLMs. In simpler terms, LLMs assist in auto-generating business names for structured data, such as columns.
This not only simplifies the data discovery process in the catalog but also ensures that data sets are labeled in a manner that’s intuitive and business-friendly.
Just as a diligent gardener meticulously labels and organizes each plant to nurture a thriving ecosystem, Amazon DataZone’s use of LLMs ensures every data ‘seed’ is accurately identified and placed, setting the foundation for a flourishing data garden.
Setting the Stage for Future Generative AI Applications
Amazon DataZone’s use of LLMs is a testament to the growing integration of Generative AI in cloud-based services.
By introducing users to the capabilities of LLMs within a data management context, Amazon DataZone is subtly preparing them for a future where Generative AI applications become more commonplace.
Amazon DataZone’s use of LLMs not only enhances its immediate data management capabilities but also positions users to embrace the broader potential of Generative AI in the future.
- Familiarity with AI-driven Processes: As users interact with the auto-generated business names in the catalog, they become more accustomed to AI-driven processes. This familiarity can reduce the learning curve when adopting other Generative AI applications in the future.
- Integration Potential: Amazon DataZone’s seamless integration with other AWS services sets the stage for users to explore and adopt other Generative AI tools available within the AWS ecosystem. For instance, users might transition from using LLMs in DataZone to leveraging Amazon Bedrock or Amazon SageMaker for more advanced Generative AI tasks.
- Data Preparedness: By ensuring that data is well-organized, labeled, and easily discoverable, Amazon DataZone sets businesses up for success when they decide to venture into more advanced Generative AI projects. A well-maintained data garden, as opposed to a compost heap, is crucial for training effective AI models.
Be More Like a Gardener
In the world of data management, we can draw many parallels between the meticulous care of a gardener and the precision required to manage vast data landscapes.
I encourage you to think and act more like a gardener! Focus on:
- Soil Preparation: Just as a gardener prepares the soil before planting seeds, Amazon DataZone prepares the data environment, ensuring it’s conducive for data growth and analysis. This can be likened to the initial setup and integration with other AWS services.
- Pruning and Maintenance: Over time, gardens require pruning to remove dead or overgrown branches, ensuring the healthy growth of plants. Similarly, Amazon DataZone’s governance features can be seen as the “pruning tools” that help businesses remove outdated or irrelevant data, keeping the data environment clean and efficient.
- Watering and Nourishment: Plants need regular watering and nourishment to grow. In the context of data, this can be likened to the continuous influx of new data and the updating of existing datasets. Amazon DataZone ensures that this influx is managed seamlessly, and data is always fresh and relevant.
- Harvesting the Fruits: After nurturing plants, a gardener reaps the fruits of their labor. Similarly, after organizing and analyzing data, businesses can “harvest” insights, making informed decisions that drive growth.
- Pest Control: Just as gardens are susceptible to pests, data environments can be vulnerable to inaccuracies, duplications, or breaches. Amazon DataZone’s governance and security features act as the “pest control,” ensuring data integrity and security.
Garden or Compost Heap?
Amazon DataZone stands as a diligent gardener, ensuring every data seed is chosen and nurtured with purpose. Unlike a compost heap that accumulates data without order, Amazon DataZone provides the tools and environment to cultivate a garden of insights, where every piece of data is valued, organized, and ready to fuel innovation.