
Shadow Deployments on AWS Part 1: Lambda@Edge
Shadow deployments have become increasingly popular among organizations as they strive to minimize downtime and ensure smooth transitions during application updates.
My goal is in this post is to help illustrate how easy and powerful it is to utilize Lambda@Edge to enable shadow deployments in a production setting for any kind of HTTP based web service.
I will soon publish a “part two” that focuses on how Amazon SageMaker’s native shadow testing capabilities also support this deployment methodology to compare new or tuned ML models vs. models already deployed in production in real-time.
While shadow deployment strategies have been around for a while now, many have been reluctant to adopt them in favor of more popular approaches such as blue-green deployments, canary deployments, rolling deployments, or feature flags. I compare and contrast the differences between these methodologies later in this post.
What is a Shadow Deployment?
Shadow deployments, sometimes referred to as dark launches or parallel deployments, involve releasing new versions of an application or infrastructure component alongside existing production versions without end users being aware of it. This allows you to test, monitor, and gather feedback on the new version in a real-world environment without affecting users. Once the new version is deemed stable and reliable, it can be seamlessly transitioned to be the primary production environment.
The main idea is to duplicate the production environment (or a portion of it) and send the same live traffic (requests) to both the primary and shadow environments simultaneously. This allows you to observe and analyze the behavior of the new version in a realistic setting while only sending responses to user requests from the actual live version.
End user requests are still replied to synchronously with responses from the production origin. Mirrored requests are asynchronously sent to the shadow deployment and responses are not returned to end users. Responses in a shadow deployment can be logged for analysis and debugging purposes.
What is Lambda@Edge?
Lambda@Edge is an extension of AWS Lambda, allowing you to run serverless functions closer to your end-users by deploying them across AWS Edge locations.
Lambda@Edge functions can be configured to automatically trigger in response to the following Amazon CloudFront events:
Viewer Request: This event occurs when an end-user or a device on the Internet makes an HTTP(S) request to CloudFront, and the request arrives at the edge location closest to that user.
Viewer Response: This event occurs when the CloudFront server at the edge is ready to respond to the end user or the device that made the request.
Origin Request: This event occurs when the CloudFront edge server does not already have the requested object in its cache, and the viewer request is ready to be sent to your backend origin web server (e.g. Amazon EC2, or Application Load Balancer, or Amazon S3).
Origin Response: This event occurs when the CloudFront server at the edge receives a response from your backend origin web server.
Using AWS Lambda@Edge for Shadow Deployments
Lambda@Edge offers a unique opportunity to enable shadow deployments in production infrastructure by using the Viewer Request event to process incoming user traffic. By using a Lambda@Edge function to process the Viewer Request event you are able to implement these capabilities:
Traffic Mirroring: Using Lambda@Edge, you can mirror incoming user requests to both the current production infrastructure and the shadow deployment. The mirrored requests will not affect user experience, as they are processed asynchronously. This allows you to evaluate the performance of your shadow deployment in a live environment. Original user requests are still replied to synchronously from the live production origin.
A/B Testing: With Lambda@Edge, you can perform A/B testing on your shadow deployment. By routing a percentage of user traffic to the new version and monitoring performance, you can gather valuable insights and make data-driven decisions regarding the rollout of your updates.
Seamless Rollouts: Once your shadow deployment has proven its stability and reliability, Lambda@Edge makes it easy to transition it into the primary production environment. With minimal configuration changes, you can reroute user traffic to the new version, ensuring a seamless user experience.
Rollback and Recovery: In the event that issues arise with the new version, Lambda@Edge enables you to quickly rollback to the previous stable version. This minimizes downtime and helps to maintain user trust in your application.
Dynamic Content Generation: Lambda@Edge can be used to generate dynamic content based on the user’s location, device, or other attributes. By deploying your serverless functions at the edge, you can generate custom content for your shadow deployment, ensuring it accurately reflects the intended changes and updates. The power of this comes into play if you are trying to add new request tokens (such as GET parameters) or other security constraints to a live application. By using a Lambda@Edge function you can simulate what impact these additions would make on a production application without potentially harming live user traffic.
Sample Shadow Deployment architectures
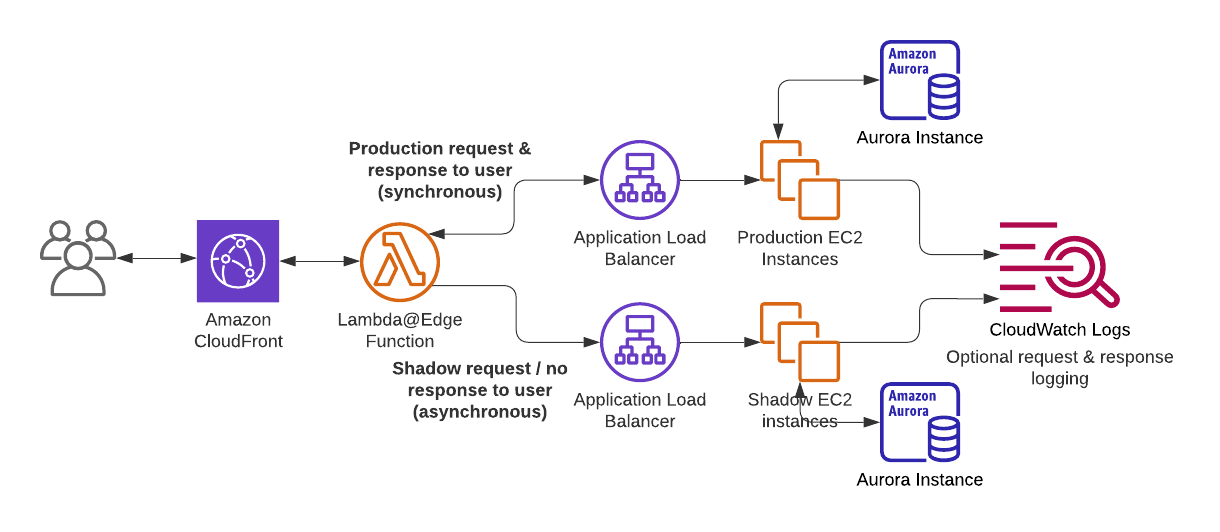
The example below illustrates how shadow deployments can be used with a traditional web stack that uses ALB, EC2, and RDS:
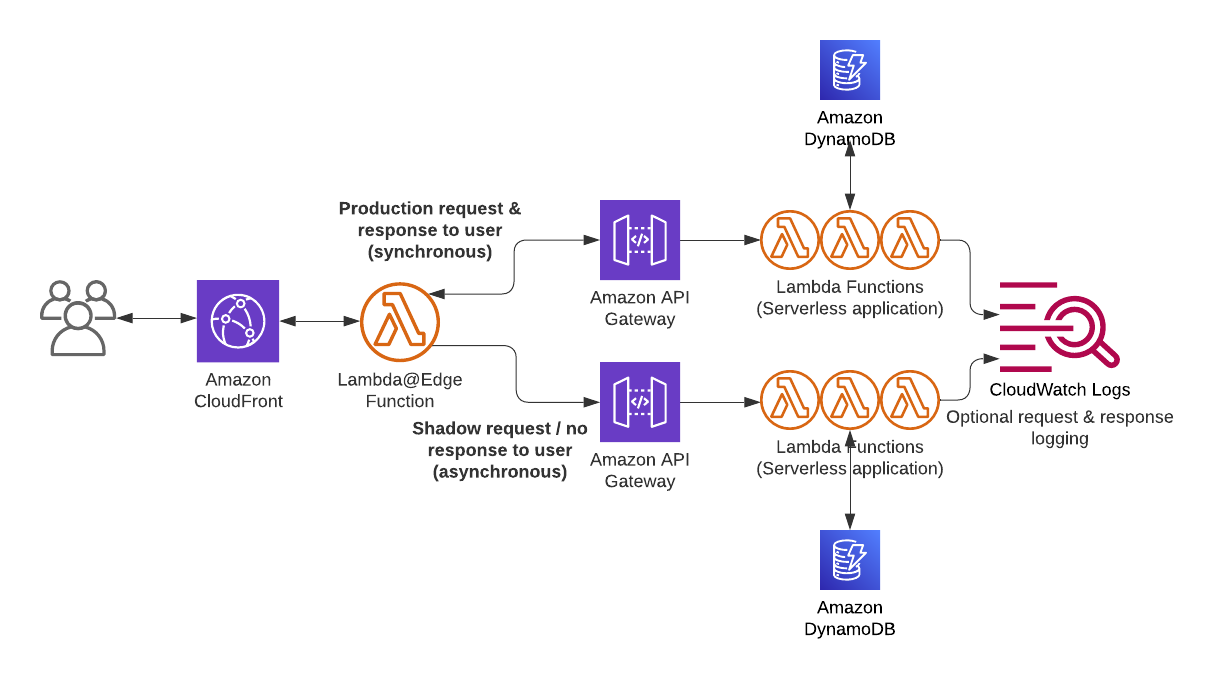
Here is another shadow deployments example, but with a Serverless application based upon API Gateway and AWS Lambda for compute:
You get the idea here… It’s entirely possible to use this Lambda@Edge architecture to front just about any kind of web service you are running in AWS – no matter where it is actually running. ECS, EKS, AppRunner, Elastic Beanstalk, so on and so forth.
The key here is that the shadow environment logs both the user request and the response since a response from the shadow environment IS NOT being returned to the actual end user. This allows you to do your on analysis and monitoring on how the shadow environment is behaving. Amazon CloudWatch Logs is a perfect for this purpose.
Alternatives would be storing response data in an Amazon Kinesis Data Stream, S3 bucket, or any other observability platform you already employ.
Lambda@Edge function example
Here is an example Lambda@Edge function that mirrors requests to a shadow origin by taking action based on the Viewer Request action triggered via a CloudFront distribution:
import urllib.request
import base64
def handler(event, context):
request = event['Records'][0]['cf']['request']
shadow_origin = "${ShadowOrigin}"
# Include query string parameters in the URL
query_string = request.get("querystring", "")
if query_string:
query_string = "?" + query_string
# Send the request to the shadow environment asynchronously
shadow_url = f'https://{shadow_origin}{request["uri"]}{query_string}'
method = request['method']
headers = request['headers']
body = request['body']
# Construct the headers dictionary
newheaders = {}
for key, values in headers.items():
newheaders[key] = values[0]["value"]
# Add the request body to the shadow request if the method is POST
if method == 'POST':
# Decode the base64 encoded body
decoded_body = base64.b64decode(body['data']).decode('utf-8')
req = urllib.request.Request(shadow_url, method=method, headers=newheaders, data=decoded_body.encode('utf-8'))
else:
req = urllib.request.Request(shadow_url, method=method, headers=newheaders)
try:
with urllib.request.urlopen(req, timeout=2) as response:
pass
except Exception as e:
print(f'Error processing shadow request: {e}')
# Continue processing the original request
return request
Notes: This code is intended to serve as a starting point. Obviously, test it and be aware of the limitations present in the Lambda@Edge operating environment. You will need to set the ${ShadowOrigin} manually (or use the CloudFormation template below that uses a Sub function to set it), as Lambda@Edge does not support environment variables. If your origin/shadow origin uses a SSL/TLS certificate it must be a valid certificate. Self-signed certificates are not supported in this example code.
CloudFormation sample
Here is an example CloudFormation template that accepts two parameters, primary origin and shadow origin. The template then deploys a net-new CloudFront distribution, creates a Lambda@Edge function preset with the shadow origin, and sends traffic to both destinations.
AWSTemplateFormatVersion: '2010-09-09'
Description: Lambda@Edge function for shadow deployments
Parameters:
ShadowOrigin:
Description: The shadow origin domain name
Type: String
PrimaryOrigin:
Description: The primary origin domain name
Type: String
Resources:
ShadowDeploymentsLambdaRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Principal:
Service:
- 'lambda.amazonaws.com'
- 'edgelambda.amazonaws.com'
Action: 'sts:AssumeRole'
ManagedPolicyArns:
- 'arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole'
- 'arn:aws:iam::aws:policy/AmazonS3ReadOnlyAccess'
ShadowDeploymentsLambdaFunction:
Type: AWS::Lambda::Function
Properties:
FunctionName: !Sub 'shadow-deployments-lambda-${AWS::StackName}'
Handler: index.handler
Role: !GetAtt ShadowDeploymentsLambdaRole.Arn
Runtime: python3.9
Code:
ZipFile: !Sub |
import urllib.request
import base64
def handler(event, context):
request = event['Records'][0]['cf']['request']
shadow_origin = "${ShadowOrigin}"
# Include query string parameters in the URL
query_string = request.get("querystring", "")
if query_string:
query_string = "?" + query_string
# Send the request to the shadow environment asynchronously
shadow_url = f'https://{shadow_origin}{request["uri"]}{query_string}'
method = request['method']
headers = request['headers']
body = request['body']
# Construct the headers dictionary
newheaders = {}
for key, values in headers.items():
newheaders[key] = values[0]["value"]
# Add the request body to the shadow request if the method is POST
if method == 'POST':
# Decode the base64 encoded body
decoded_body = base64.b64decode(body['data']).decode('utf-8')
req = urllib.request.Request(shadow_url, method=method, headers=newheaders, data=decoded_body.encode('utf-8'))
else:
req = urllib.request.Request(shadow_url, method=method, headers=newheaders)
try:
with urllib.request.urlopen(req, timeout=2) as response:
pass
except Exception as e:
print(f'Error processing shadow request: {e}')
# Continue processing the original request
return request
CloudFrontDistribution:
Type: AWS::CloudFront::Distribution
Properties:
DistributionConfig:
Enabled: true
PriceClass: PriceClass_100 # Use only local edge locations for this example to speed deployment
DefaultCacheBehavior:
TargetOriginId: primaryOrigin
ViewerProtocolPolicy: redirect-to-https
CachePolicyId: 4135ea2d-6df8-44a3-9df3-4b5a84be39ad # AWS managed 'CachingDisabled' policy
OriginRequestPolicyId: 216adef6-5c7f-47e4-b989-5492eafa07d3 # AWS managed 'AllViewer' policy
AllowedMethods:
- OPTIONS
- HEAD
- GET
- PUT
- POST
- PATCH
- DELETE
LambdaFunctionAssociations:
- EventType: 'viewer-request'
LambdaFunctionARN: !Ref ShadowDeploymentsLambdaFunctionVersion
IncludeBody: true
Origins:
- Id: primaryOrigin
DomainName: !Ref PrimaryOrigin
CustomOriginConfig:
HTTPPort: 80
HTTPSPort: 443
OriginProtocolPolicy: 'https-only'
OriginSSLProtocols:
- TLSv1
- TLSv1.1
- TLSv1.2
ShadowDeploymentsLambdaFunctionVersion:
Type: 'AWS::Lambda::Version'
Properties:
FunctionName: !Ref ShadowDeploymentsLambdaFunction
Differences between Shadow Deployments and other deployment strategies
Here’s how shadow deployments differ from other common deployment strategies:
Blue-green deployments: In blue-green deployments, two separate but identical environments (blue and green) are maintained. The live traffic is directed to one environment while the other environment is updated with the new version. Once the new version is ready and tested, traffic is switched to the updated environment. Blue-green deployments aim to minimize downtime during updates but do not provide the same real-world testing opportunities as shadow deployments.
Canary deployments: Canary deployments involve gradually rolling out new application versions or infrastructure changes to a small percentage of users before fully deploying them. This allows you to monitor the performance, stability, and potential issues of the new version before it is widely released. While canary deployments share some similarities with shadow deployments, they still involve exposing the new version to a subset of users, which shadow deployments avoid by routing all users to the primary environment.
Rolling deployments: Rolling deployments consist of incrementally updating instances of an application or service while maintaining availability. A portion of instances is updated at a time, and the deployment proceeds once the updated instances are confirmed to be stable. Rolling deployments minimize downtime and reduce risk, but they do not provide the same level of isolation and real-world testing as shadow deployments.
Feature flags: Feature flags (or feature toggles) are used to enable or disable certain features in an application at runtime. This allows you to control the release of new features by selectively enabling them for specific users or environments. Although feature flags provide a granular level of control, they do not offer the same level of testing and monitoring as shadow deployments.